一致性与共识算法
本文从《数据密集型引用系统设计》、Paxos lecture (Raft user study)(https://www.youtube.com/watch?v=JEpsBg0AO6o) 各截取了部分。
挑战
故障

数据:
- 磁盘: 4% 年损坏率
- 服务器宕机时间: 0.1% 或更长
- IDC间丢包率: 5% ~ 30%
下面是几种分布式系统下典型的问题:
- 当通过网络发送数据包时,数据包可能会丢失或者延迟。同样,回复也可能会丢失或延迟。所以如果没有收到回复,并不能确定消息是否发送成功。
- 节点的时钟可能会与其他节点存在明显的不同步,时钟还可能会突然向前跳跃或者倒退,依靠精准的时钟存在一些风险,没有特别简单的方法来精确测量时钟的偏差范围。
- 进程可能在执行过程中的任意时候遭遇长度未知的暂停(一个重要的原因是垃圾回收),结果它被其他节点宣告失效,尽管后来又恢复执行,却对中间的暂停毫无所知。
部分失效可能是分布式系统的关键特征。只要软件试图跨节点做任何失效,就有可能出现失败,或者随机变慢,或者根本无应答(最终超时)。对于分布式环境,我们目标是建立容忍部分失效的软件系统,这样即使某些部件发生失效,系统整体还可以继续运行。
线性化与CAP理论
线性化:表现得好像只有一个数据副本,且其上的所有操作都是原子的。
为什么要线性化?
非线性化系统的问题:
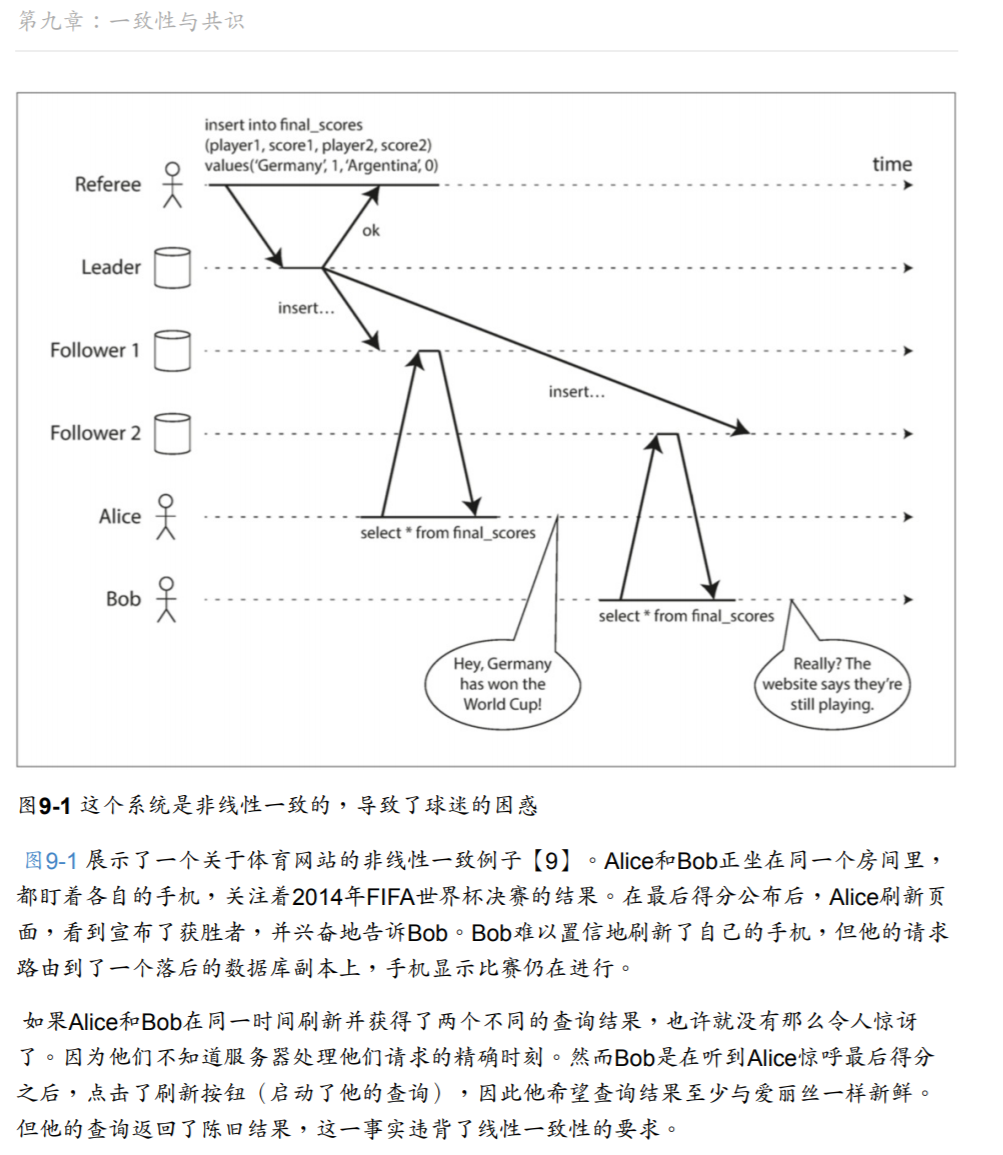
上面违背线性化只产生了一个比较小的问题,仅仅是展示页面不一致。但是如果核心业务违背线性化,可能导致严重问题。常见的就是集群选主,可能会出现两个主,导致脑裂。
常见复制算法,对线性化的支持:
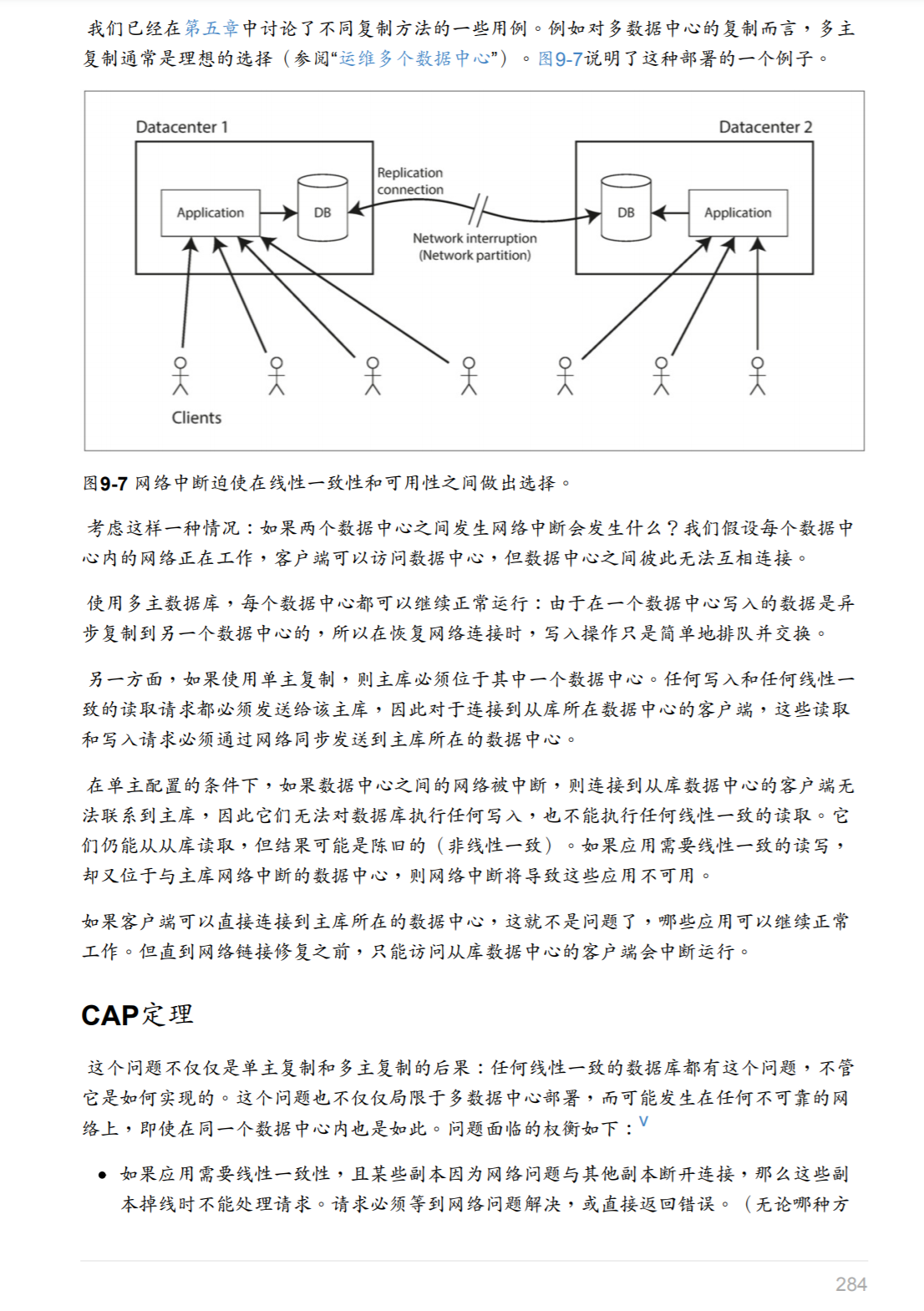
- 主从复制(部分支持)
- 只有主写入读取的话,其他都是备份的情况下,是线性化的。但是不能做高高可用。
- 异步复制、主脑裂、从读等情况,不可线性化。
- 多主复制(不可线性化)
- 多副本冲突
- 无主复制(可能不可线性化)
- 能够实现高可靠、高可用性、数据完整有保证
- 会出现脏读、更新丢失等情况
- 具体看ddia吧,不展开了,用的比较少
- 共识算法(可线性化)
- 具体之后讨论。
线性化的代价以及CAP理论:

FLP
FLP 不可能定理是分布式系统领域最重要的定理之一,它给出了一个非常重要的结论:在网络可靠并且存在节点失效的异步模型系统中,不存在一个可以解决一致性问题的确定性算法。
In this paper, we show the surprising result that no completely asynchronous consensus protocol can tolerate even a single unannounced process death. We do not consider Byzantine failures, and we assume that the message system is reliable it delivers all messages correctly and exactly once.
这个定理其实也就是告诉我们不要浪费时间去为异步分布式系统设计在任意场景上都能够实现共识的算法,异步系统完全没有办法保证能在有限时间内达成一致。
注意这里的异步系统,参照DDIA第八章理论系统模型与现实的解释:在异步系统中,一个算法不会对时机做任何的假设,甚至里面根本没有时钟。
如果算法可以使用超时或者其他方式来检测崩溃的节点(即使怀疑可能是误报),那么可以实现稳定的共识方案。另外即使算法使用了随机数来检测节点故障也可以绕过FLP结论。
拜占庭将军问题
拜占庭将军问题是Lamport 在 The Byzantine Generals Problem 论文中提出的分布式领域的容错问题,它是分布式领域中最复杂、最严格的容错模型。
在该模型下,系统不会对集群中的节点做任何的限制,它们可以向其他节点发送随机数据、错误数据,也可以选择不响应其他节点的请求,这些无法预测的行为使得容错这一问题变得更加复杂。
这个问题在特定场景是合理的。例如:
- 在航天领域,计算机内存或CPU寄存器的数据可能会被辐射而发生故障,导致以不可预知的方式响应其他节点。这种情况西如果将系统下线,代价将异常昂贵,飞行控制系统必须做到容忍拜占庭故障。
- 在有多个参与者的系统中,某些参与者可能会作弊或者欺骗他人。这时节点不能完全相信另一个节点所发送的消息,它可能是恶意的。例如,像比特币和其他区块链一样的点对点网络就是让互不新人的当时方就某项交易达成一致,且不依赖于集中的机制。
不过在我们一般日常的系统里,不太考虑拜占庭将军问题。不过,系统中的bug可以认为是拜占庭式故障,但是如果只有一种实现,被部署在所有位置。那么出问题了,显然会全军覆没。如果要解决这个问题,只有写好几种不同的实现,然后希望只有部分节点中有bug。这显然是不合算的。
共识算法
我们这里的共识算法主要目的是为了在达到线性化的效果的情况下,能做到足够的容错。允许多个节点中,部分在出现上述故障部分描述的情况下,依旧能够对外提供服务。
同时假定系统中不存在拜占庭式错误,即使真的存在,研究表明只要发生拜占庭故障的节点数小于三分之一,也可以达成共识。
paxos
- 一个可靠的存储系统:基于多数派读写
- 每个paxos实例用来存储一个值
- 用两轮RPC来确定一个值
- 一个值’确定’后不能被修改
- ‘确定’指被多数派接收写入
- 强一致性
条件
存储必须可靠:没有数据丢失和错误
容忍:
- 消息丢失(节点不可达)
- 消息乱序
算法流程

首先,每个Acceptor需要持久化三个变量(minProposal、acceptedProposal、acceptValue)。最开始minProposal = acceptedProposal = 0,acceptValue = null。算法有两个阶段:P1(Prepare阶段)、P2(Accept阶段)
P1(Prepare阶段)
-
P1a:
- 选择一个新的提议序号n,这个序号要全局唯一且递增,一般来说是利用时间+服务器ip
- 提议者(proposer)向所有接收者(acceptor)发起RPC(Prepare(n)),消息中包含提议序号n。
-
P1b:接收者(acceptor)接收到Prepare(n),会做如下决策:
1 2 3 4 5 6if n > minProposal 回复yes 同时minProposal = n (持久化) 返回(acceptedProposal, acceptValue) else 回复no -
P1c:提议者(proposer)会等待大多数(超过半数)接收者(acceptor)的响应。
- 接收到响应,并且为yes,选取acceptedProposal最大的acceptValue为新的acceptValue。
- 返回的acceptValue为null时,acceptedProposal肯定为0,这时候根据算法会选取自己的值为acceptValue。
- 半数以上的回复是yes,进入下一阶段P2。否则,n自增,重复P1a。
P2(Accept阶段)
-
P2a:提议者(proposer)发起RPC(Accept(n, value)),value为p1选出的acceptValue。
-
P2b:接收者(acceptor)接收到Accept(n, value),会做如下决策:
1 2 3 4 5 6 7if n >= minProposal 回复yes 同时minProposal = acceptedProposal = n(持久化) acceptValue = value return minProposal else 回复no -
P2c:提议者(proposer)收到半数以上的yes,并且minProposal = n,则算法结束。否则n自增,重复P1a
示例
接下来用一些例子来说明提议竞争的状态,以及关键点在于第二次提议的准备阶段。
总共有三种可能。
一、已经选定了之前的值

简单解释下图形的意思:
-
有两个请求,X向S1请求,Y向S5请求。
-
P3.1表示Prepare阶段,提议序号3.3,高位顺序数3,低位服务器号5。
-
A4.5X表示Accept阶段,提议需要4.5,高位顺序数4,地位服务器号5,接受值X。
-
在第二个提议请求来之前,第一个提议请求已经选定了值,也就是说值 X 已经被集群的大多数服务器所接受。
-
第二个提议请求也需要大多数服务器得到响应,所以一定可以保证会至少有一个准备(Prepare)请求会到达与前一个请求相同的服务器,这里是 S3 。
-
服务器 S5 会发现已经接受的值 X ,当它响应准备请求(Prepare)时,它会放弃 Y 值,并为在所有接受(Accept)请求时使用 X 值。
- 算法选取回复yes中acceptedProposal最大的,那么S3的是3.1,value被替换为X。
-
服务器 S5 会成功,选定值为 S1 提议的 X 。
后面两种情况的前提是前值没有被选定的情况下,第二次请求进入了准备阶段(Prepare Phase)
二、前值没有被选定,但对新提议可见

有可能前一次的提议正在处于接受值的过程中,第二次提议恰好见到了其中的接受值。
这个场景和第一个场景类似,最终结果是A4.5X。注意这里其实S5并不需要知道S1、S2的情况,不管S1\S2是否接受X,最终选出来的都是X。
三、前值没有被选定,对新提议也不可见

提议A3.1X被拒绝了,因为4.5 > 3.1,X的提议失败了,等待下次重试,Y的提议被接受。
至此,足以说明 Paxos 协议在竞争状态下是安全的,无论如何竞争,最终都会选定某一值并达成一致。但是,这并不能说明基础 Paxos 协议是可用的(Live),可能会发生一组提议相互阻碍的情况,最终不会有任何选定值。下面会对此进行说明。
可用性
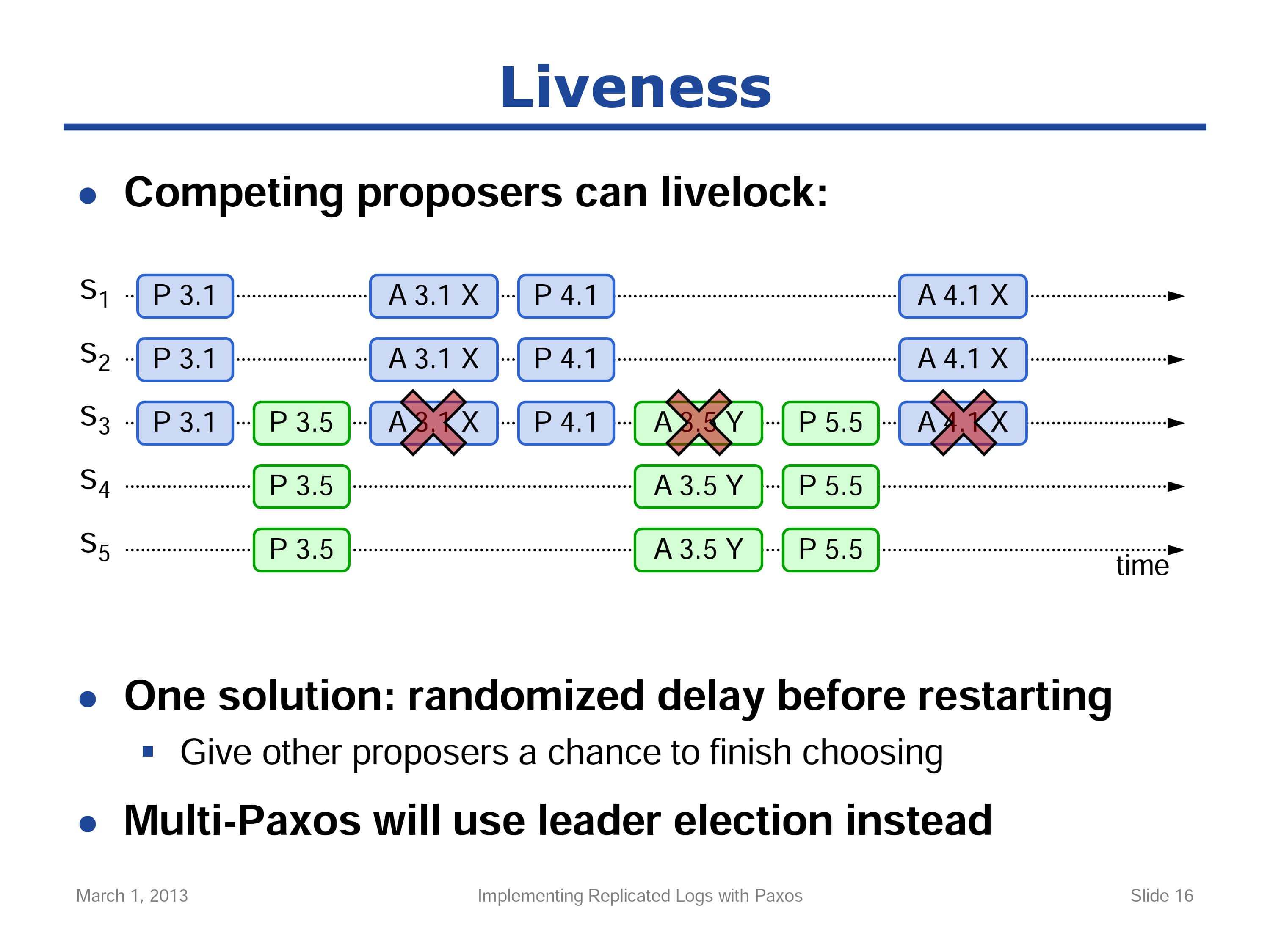
假设服务器 S1 成功接收到请求,并处于准备阶段(P 3.1)。在接受值 X 之前(A 3.1 X),另外一个服务器 S5 正处于它的准备阶段(P 3.5),这会阻止前序值的接受(A 3.1 X)。然后 S1 会重新选择提议序号并再次开始提议过程(P 4.1),假设它正进入了第二轮的准备阶段,在接受值之前,服务器 S5 正试图完成接受值的选定 Y (A 3.5 Y),不过此时因为(P 4.1)的序号高于(A 3.5 Y),所以它阻止了(A 3.5 Y)的接受,这样 S5 的提议就失败了,然后 S5 又重新开始下一轮的提议,如此往复,这个过程会无限循环下去。
为了不发生活锁,Paxos 需要以某种补充机制来保证它可以正确运行。
- 给重新开始一个随机的延时,让其他提议者有机会完成。
- 在多 Paxos 协议(Multi-Paxos)下,将多写转变为单写,选出一个Leader。
其他
超时等错误:等价于拒绝
两个阶段的多数派不需要完全相同
读一致:
- leader
- Paxos Quorum Reads
- …
常见的应用
到此为止仅仅是一个值的决议,用处比较小。实践一般是使用paxos协议确定一堆有序的值,实现一个键值存储。具体怎么做的我还在研究。
-
节点任务分配
- 主从分配
- 分区ID分配:主从可以看作分区id分配的特化版
- 分布式锁
-
服务发现
-
用zookeeper\etcd做服务发现的比较多。
-
不过有些人认为服务发现不需要共识。常见的DNS、Eureka、我们的naming都没有用共识实现。
-
-
成员服务
- 心跳检测